优惠券秒杀
1.1 全局唯一ID
1.1.1 背景
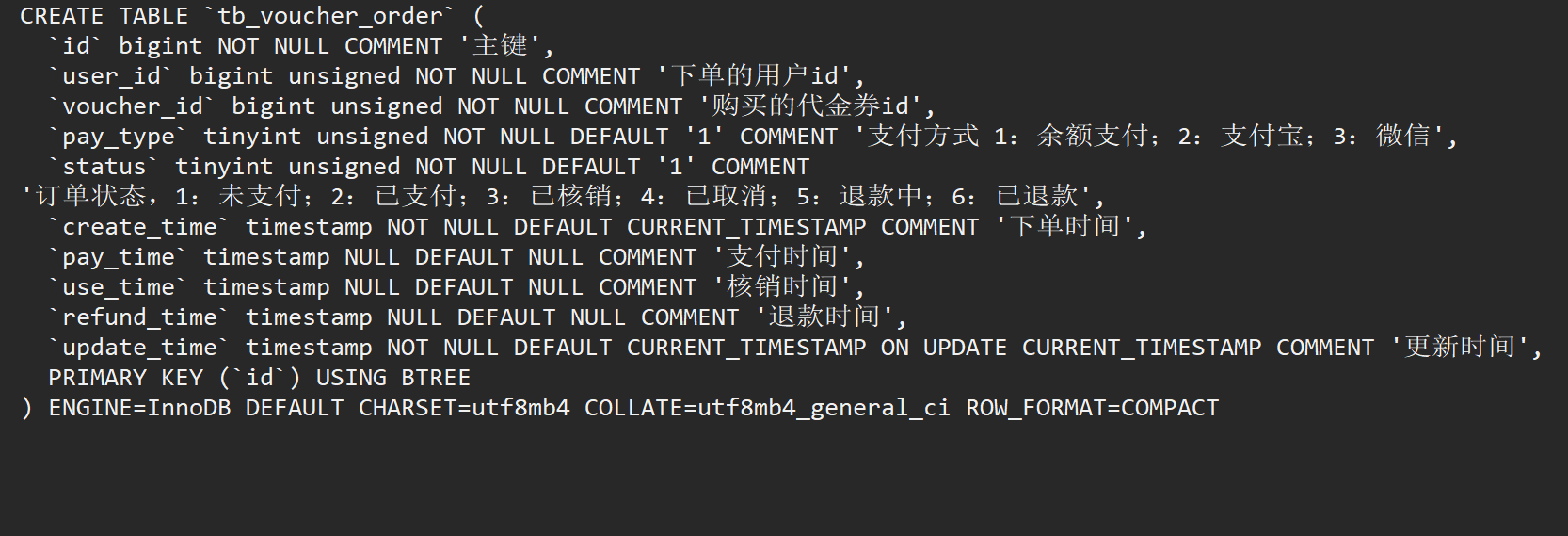
优惠券是黑马点评项目中唯一的商品,其表结构如下图所示,voucher_id代表购买的优惠券的id,我们需要一个字段来表示订单编号,传统方法是自增主键id+订单id,但是考虑到之后数据量大之后,要进行分库分表操作,这样主键id就可能在多个表中重复,这样会让我们的订单的唯一性被破坏。
我们使用全局唯一id来作为主键,这里使用了一种类雪花算法,它的结构如下图所示,而这种ID也是对数据库的B+树索引友好的,如果基于等值查询
id = #{id},和原来的自增主键id的性能是一样的,如果基于范围查询(a <= id <= b),由于其时间戳的原因,临近时间生成的ID,在B+树上的位置也是比较近的,不会落后自增id多少。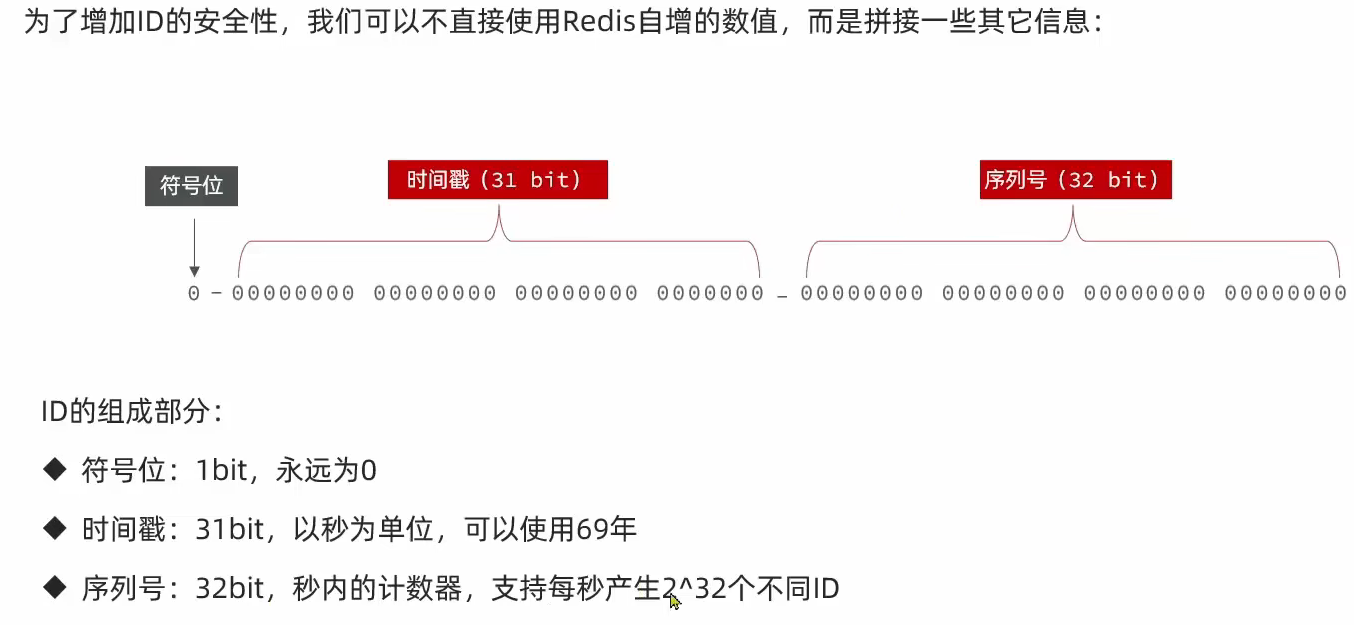
1.1.2 概念
全局ID生成器,是一种在分布式系统中用来生成全局唯一ID的工具,一般要满足一下特性:
- 唯一性
- 高可用
- 高性能
- 递增性(用于B+树索引)
- 安全性
这里我们使用Redis的 INCR 功能做全局ID生成器,其非常满足高可用和高性能的特点
1.1.3 实现
package com.hmdp.utils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.*;
import java.time.format.DateTimeFormatter;
/**
*
* 全局ID生成器
*
* @author weiqiang
* @date 2026/04/06
*/
@Component
public class RedisIdWorker {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 开始时间戳,20050322距今秒数
*/
private static final Long BEGIN_TIME = 1111449600L;
/**
* 32位序列号
*/
private static final int COUNT_BITS = 32;
/**
*
* 生成全局ID
*
* @param keyPrefix 业务前缀
* @return {@link Long }
*/
public Long generateId(String keyPrefix) {
StringBuilder id = new StringBuilder();
// 1. 第一位为符号位永远为0
id.append(0);
// 2. 第2到第32位为时间戳,这里我们选择距离2005年3月22日的秒数
long now = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC);
Long timeStamp = now - BEGIN_TIME;
id.append(StringUtils.leftPad(String.valueOf(timeStamp), 31, "0"));
// 3. 序列号,从0开始
String date = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
Long serialNumber = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + date);
return timeStamp << COUNT_BITS | serialNumber;
}
}1.2 实现优惠券秒杀下单
1.2.1 背景
本项目维护了两种优惠券,一种是一般优惠券,另一种是特价优惠券,特价优惠券是限时限量发放,所以,这里需要秒杀逻辑。
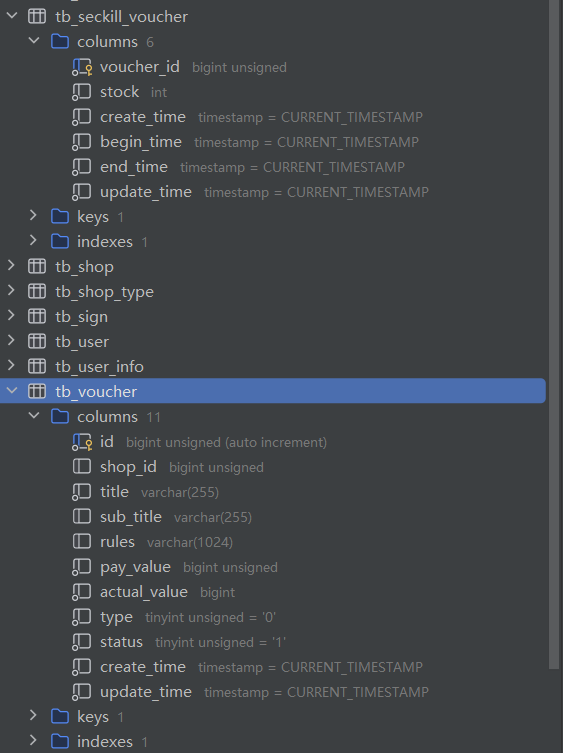
数据库中维护了两张表,一张是优惠券基本信息表,两种优惠券都需要填写这张表;另一张是秒杀优惠券表,只有特价优惠券需要填写这张表,以下是这两张表的字段展示。
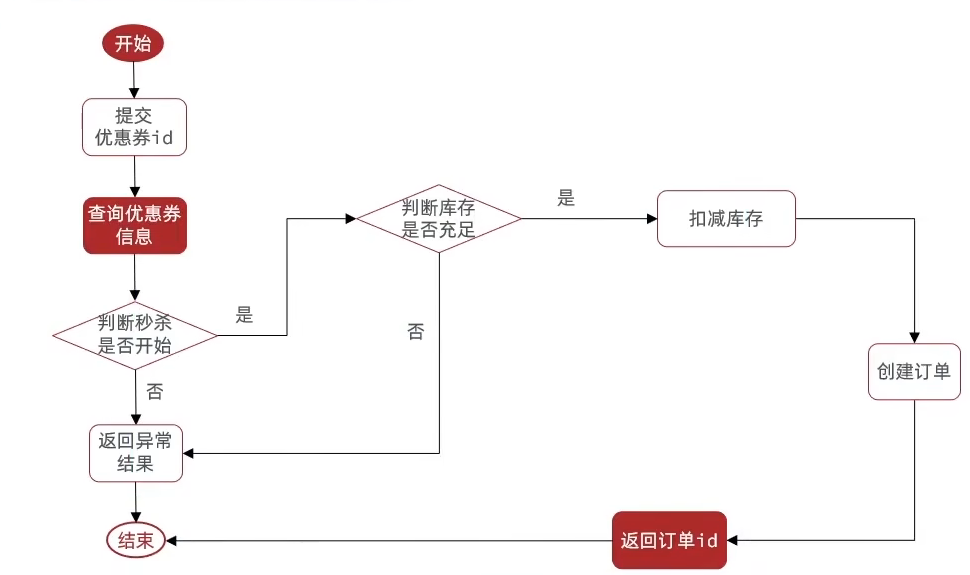
1.2.2 实现优惠券秒杀的下单功能
下单时要判断两点:
- 是否在秒杀时间段内,不在秒杀时间段内无法下单
- 库存是否充足,不足无法下单
业务流程图如下:
初步实现(之后可将秒杀优惠券放到Redis中)
java@Autowired private RedisIdWorker redisIdWorker; @Autowired private ISeckillVoucherService seckillVoucherService; /** * 优惠券秒杀下单 * * @param voucherId * @return {@link Result } */ @Override @Transactional(rollbackFor = Exception.class) public Result seckillVoucher(Long voucherId) { // 1. 查询优惠券信息 SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId); if (seckillVoucher == null) { return Result.fail("订单不存在!"); } // 2. 是否在时间段内,不在时间段内需要返回错误信息 LocalDateTime beginTime = seckillVoucher.getBeginTime(); LocalDateTime endTime = seckillVoucher.getEndTime(); if (LocalDateTime.now().isBefore(beginTime) || LocalDateTime.now().isAfter(endTime)) { return Result.fail("请在规定时间内抢购!"); } // 3. 判断库存是否充足 // 4. 库存不足返回错误信息 if (seckillVoucher.getStock() < 1) { return Result.fail("库存不足!"); } // 5. 库存充足开始下单逻辑 // 5.1 扣减库存 boolean success = seckillVoucherService.update() .setSql("stock = stock - 1") .eq("voucher_id", voucherId) .update(); if (!success) { // 扣减失败 return Result.fail("库存不足!"); } // 5.2 下单 VoucherOrder voucherOrder = new VoucherOrder(); Long orderId = redisIdWorker.generateId("order"); voucherOrder.setId(orderId); voucherOrder.setUserId(UserHolder.getUser().getId()); voucherOrder.setVoucherId(voucherId); save(voucherOrder); // 5.3 返回订单ID return Result.ok(orderId); }
1.3 超卖问题
1.3.1 问题
上方实现的代码有超卖问题,多个线程并发时,会同时对临界区的资源进行操作。
1.3.2 两种解决方案
- 乐观锁
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其他线程对数据做了修改。
- 如果没有修改则认为是安全的,自己才更新数据。
- 如果已经被其他线程修改说明发生了安全问题,此时可以重试或异常。
- 存在成功率低的问题
- 悲观锁
- 认为线程安全问题一定会发生,因此在操作数据前先获取锁,确保线程串行执行。
- 例如Synchronized、lock都属于悲观锁
1.3.3 代码实现
这里只改了一行代码,就解决了超卖问题。由于悲观锁影响并发性能,这里使用了乐观锁的思想,乐观锁最常用的实现方式是给数据加一个版本号,每当有线程进来的时候,都先查一遍当前版本号,在改动数据前再查一遍,如果版本号不一致则重试或抛异常,只有版本号一致才允许修改(CAS:Compare And Switch)。这里我们可以检查库存是否一致。
但是这种实现方法对于该业务有些缺点,试想一种场景,两个线程同时过来,修改库存,库存在还剩很多的时候,第二个线程却因为第一个线程进行了秒杀操作,库存变了,在还可以出单的情况下却出现了秒杀失败的场景,降低了系统的并发。所以这里代码有个小巧思,我们只判断 stock >= 1 的情况,只要库存大于等于1,我们就允许出单,只有库存为1时,我们才限制多个线程的并发修改的情况。
代码实现:
@Override
@Transactional(rollbackFor = Exception.class)
public Result seckillVoucher(Long voucherId) {
// 1. 查询优惠券信息
SeckillVoucher seckillVoucher = seckillVoucherService.getById(voucherId);
if (seckillVoucher == null) {
return Result.fail("订单不存在!");
}
// 2. 是否在时间段内,不在时间段内需要返回错误信息
LocalDateTime beginTime = seckillVoucher.getBeginTime();
LocalDateTime endTime = seckillVoucher.getEndTime();
if (LocalDateTime.now().isBefore(beginTime) || LocalDateTime.now().isAfter(endTime)) {
return Result.fail("请在规定时间内抢购!");
}
// 3. 判断库存是否充足
// 4. 库存不足返回错误信息
if (seckillVoucher.getStock() < 1) {
return Result.fail("库存不足!");
}
// 5. 库存充足开始下单逻辑
// 5.1 扣减库存
boolean success = seckillVoucherService.update()
.setSql("stock = stock - 1")
.eq("voucher_id", voucherId)
// 改动处
.ge("stock",1)
.update();
if (!success) {
// 扣减失败
return Result.fail("库存不足!");
}
// 5.2 下单
VoucherOrder voucherOrder = new VoucherOrder();
Long orderId = redisIdWorker.generateId("order");
voucherOrder.setId(orderId);
voucherOrder.setUserId(UserHolder.getUser().getId());
voucherOrder.setVoucherId(voucherId);
save(voucherOrder);
// 5.3 返回订单ID
return Result.ok(orderId);
}1.4 一人一单
1.4.1 背景
- 商家搞这种活动,促销优惠券,其中一个目的就是拓展用户量,但是如果所有的优惠券都被一个人抢到了,那么商家的目的自然落空。
- 所以我们做一人一单的限制
1.4.2 解决方案
在查询库存之前,查询订单表,查看是否该用户已经买了该优惠券,sql条件是
user_id = #{userId} and voucher_id = #{voucherId}具体代码逻辑
java// 5. 一人一单 // 5.1 根据用户ID和优惠券ID查询数据库,是否存在 Long userId = UserHolder.getUser().getId(); Integer count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); if (count > 0) { // 5.2 存在返回错误信息 return Result.fail("您已经抢购过该优惠券!"); }这中间有问题,在单体项目的时候,两个线程,一个还没有将订单写入数据库,另一个线程过来,查询到了count值,也是会进入下方逻辑,下单。
我们在查询一人一单、扣减库存和下单三者操作中加上锁,锁的粒度选择userId.tostring().intern(),这里使用intern确保能锁住同一个对象。并且在三个业务逻辑上加上事务。
java@Transactional public Result createVoucherOrder(Long voucherId) { // 5. 一人一单 // 5.1 根据用户ID和优惠券ID查询数据库,是否存在 Long userId = UserHolder.getUser().getId(); Integer count = query().eq("user_id", userId).eq("voucher_id", voucherId).count(); if (count > 0) { // 5.2 存在返回错误信息 return Result.fail("您已经抢购过该优惠券!"); } // 6. 库存充足开始下单逻辑 // 6.1 扣减库存 boolean success = seckillVoucherService.update() .setSql("stock = stock - 1") .eq("voucher_id", voucherId) .ge("stock", 1) .update(); if (!success) { // 扣减失败 return Result.fail("库存不足!"); } // 7. 下单 VoucherOrder voucherOrder = new VoucherOrder(); Long orderId = redisIdWorker.generateId("order"); voucherOrder.setId(orderId); voucherOrder.setUserId(UserHolder.getUser().getId()); voucherOrder.setVoucherId(voucherId); save(voucherOrder); // 8. 返回订单ID return Result.ok(orderId); }在其他方法调用,这里需要注意,需要获取代理对象执行事务,否则this.AOP代理方法()是不会执行的
javaLong userId = UserHolder.getUser().getId(); synchronized (userId.toString().intern()) { IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy(); return proxy.createVoucherOrder(voucherId); }这样在单体项目中就实现了一人一单的业务逻辑,可是在集群模式下,每台JVM机都有一个锁,都会有一个线程获取到这个锁,这样在极高并发情况下,每台JVM都会有个线程成功。
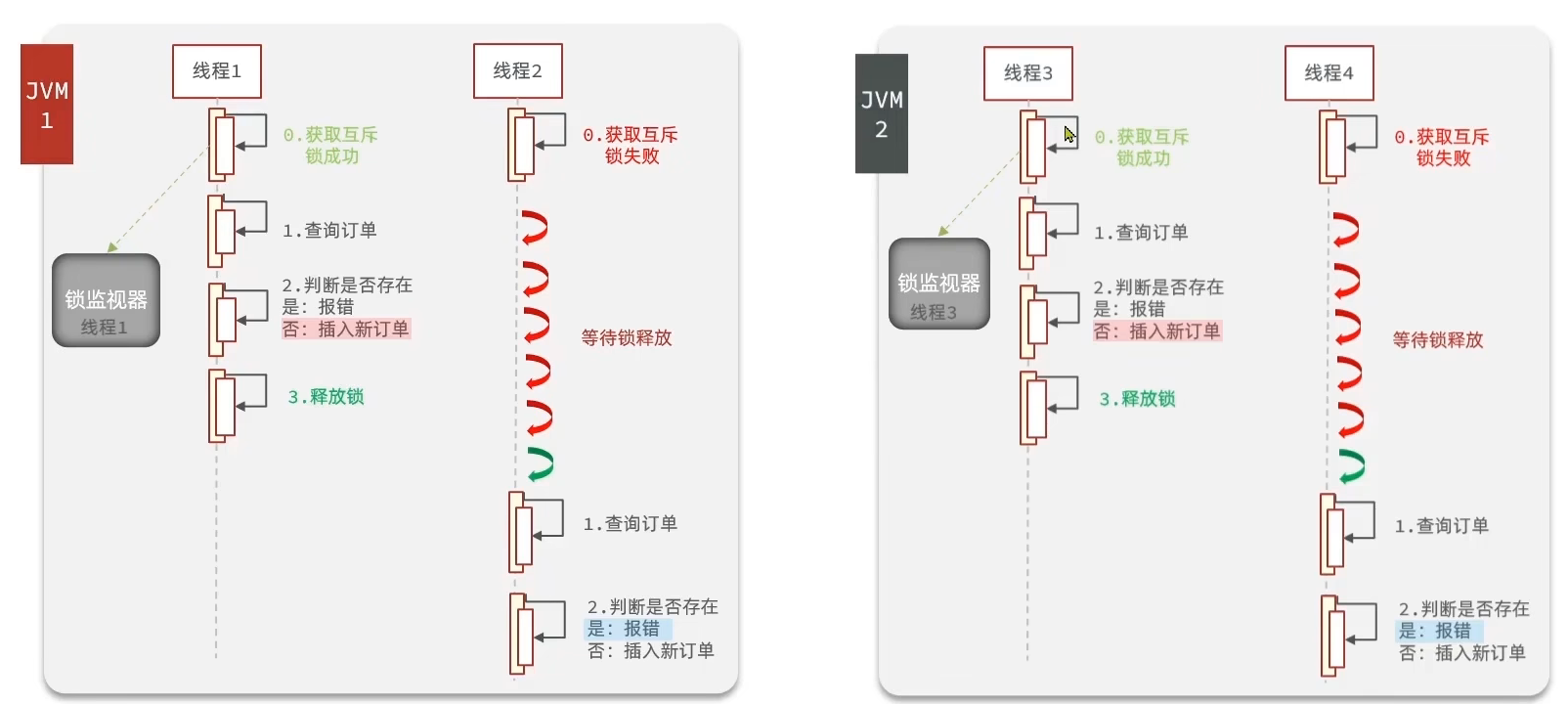
1.5 分布式锁
1.5.1 背景
分布式锁即在多个JVM外部设立一个锁监视器,JVM全部请求这个外部的锁监视器,从而实现这个锁监视器对所有JVM生效。
结构图
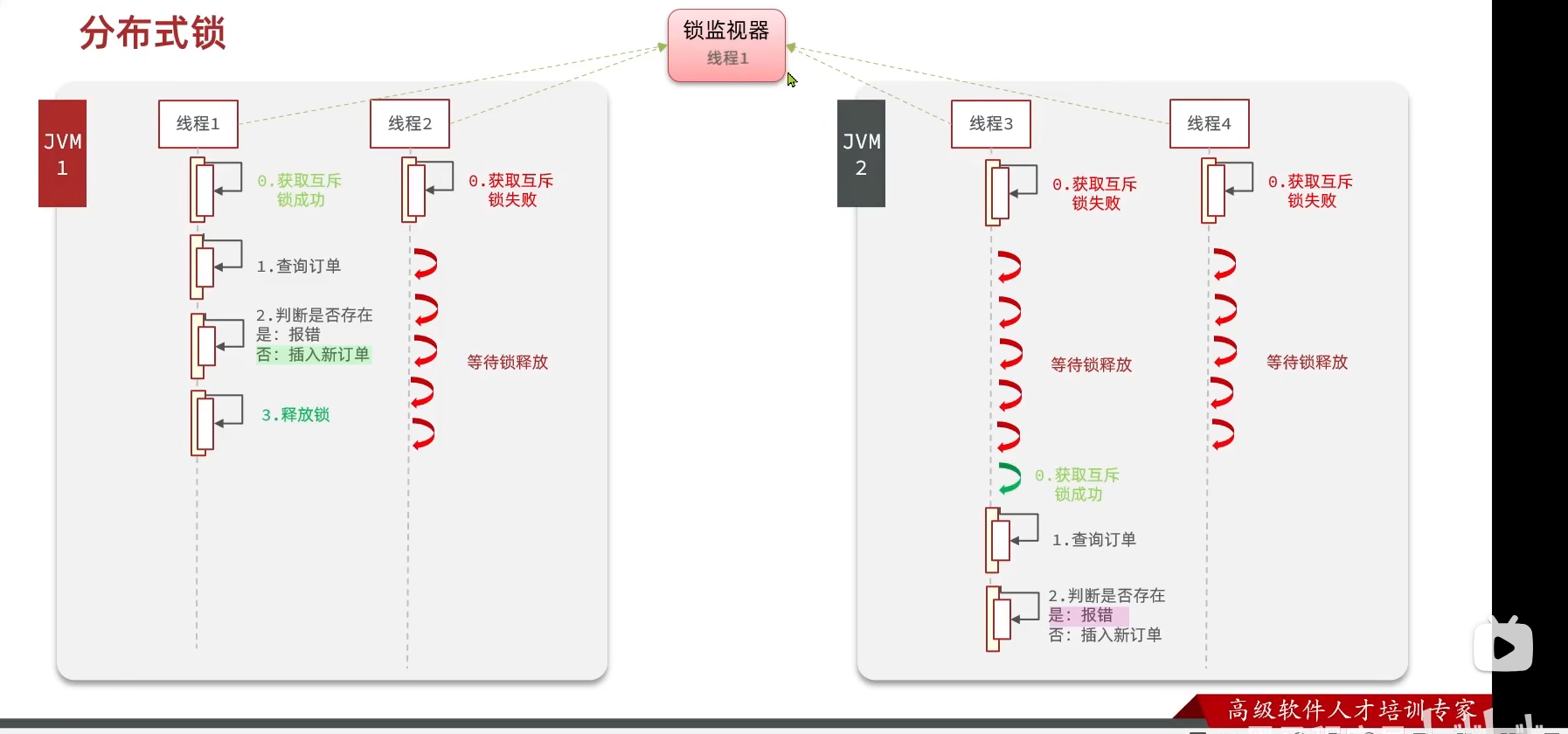
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁,满足以下特性:
- 多进程可见
- 互斥
- 高可用
- 高性能
- 安全性
- 其他功能性特点
分布式锁的实现
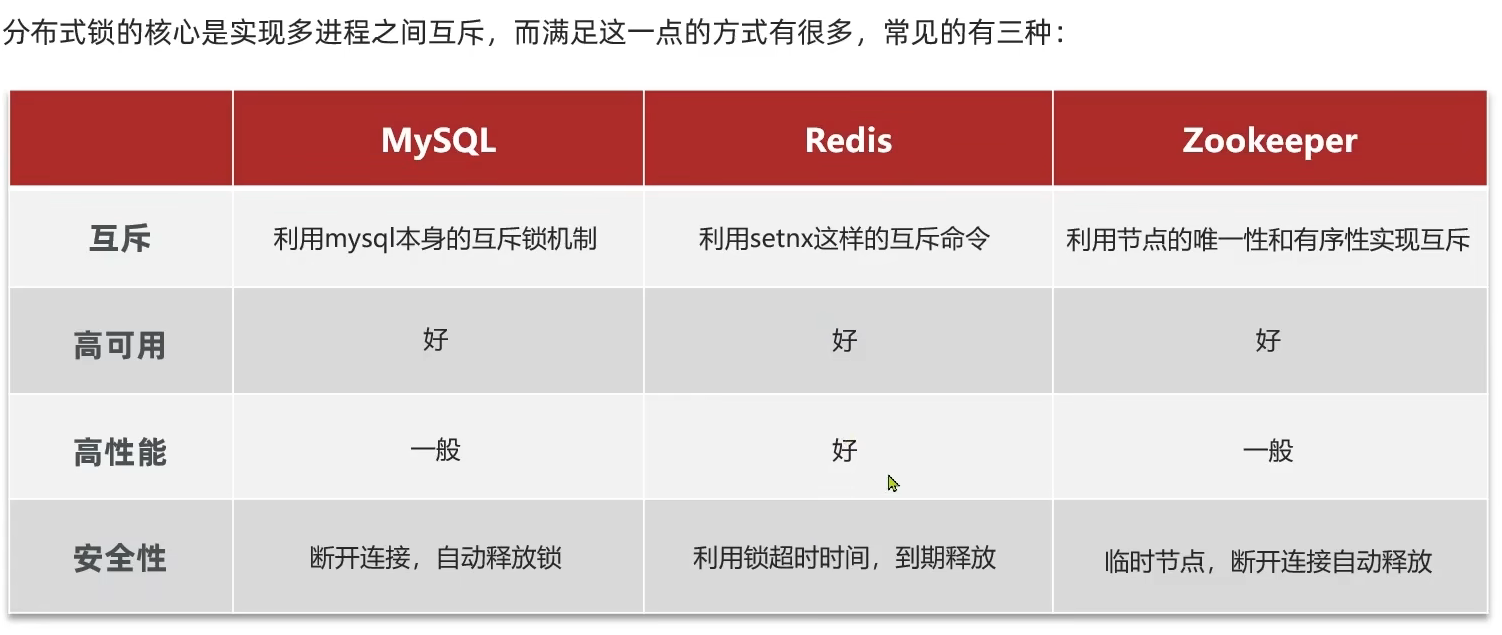
1.5.2 基于Redis的分布式锁
1. 基本实现
- 获取锁:
set lock thread1 NX EX 10,NX互斥,只有不存在才可以创建,EX表示过期时间 - 释放锁:
del key,这里超时会自动释放
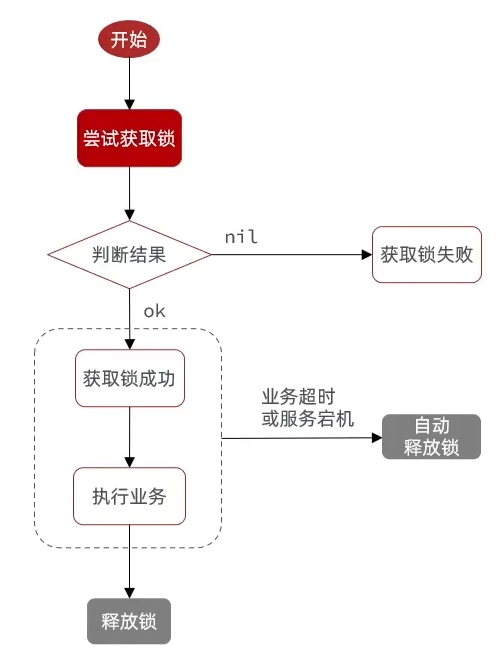
2. 目前的问题
- 一个线程可以释放另一个线程的锁
- 如果一个线程在预期时间内没有完成业务,以至于超过了锁的最大持有时间,存在线程没有完成任务锁就失效的问题。并且如果该线程在完成任务释放锁时,如果有另外一个线程持有锁,存在释放别人的锁的问题。
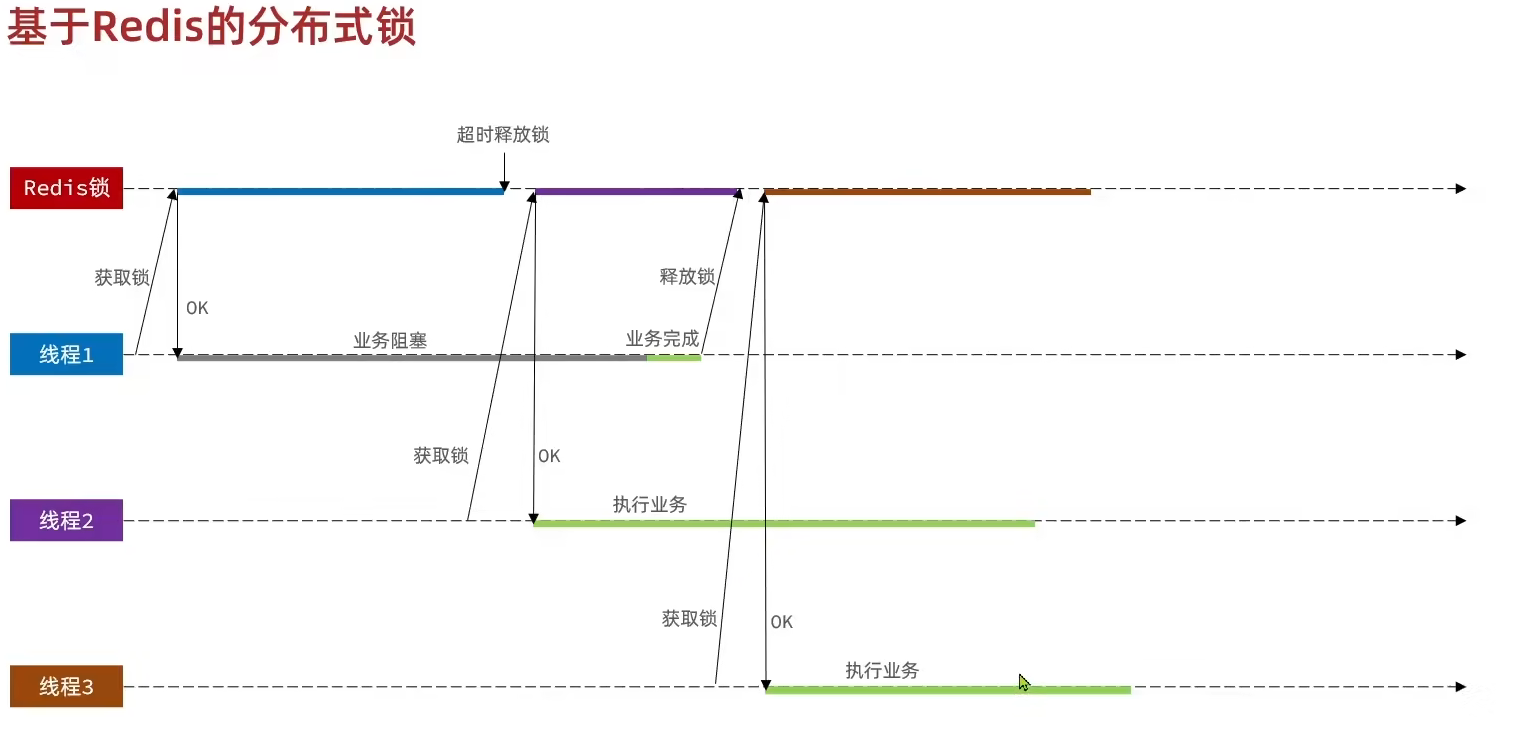
3. 解决方法
为了解决错误释放掉别人的锁的问题,我们可以在释放锁之前先拿取锁的值,判断是否为当前线程的锁,如果不是当前线程的锁就什么也不做。
代码
private static final String ID_PREFIX = UUID.randomUUID().toString().replace("-", "") + "-";
@Override
public boolean tryLock(long timeoutSec) {
// 获取线程ID作值
String threadId = ID_PREFIX + Thread.currentThread().getId();
Boolean success = stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX + name, threadId, timeoutSec, TimeUnit.SECONDS);
// 防止自动拆箱返回NULL报NPE
return Boolean.TRUE.equals(success);
}
@Override
public void unlock() {
String threadId = ID_PREFIX + Thread.currentThread().getId();
String value = stringRedisTemplate.opsForValue().get(KEY_PREFIX + name);
// 确实是自己的锁
if ((threadId).equals(value)) {
stringRedisTemplate.delete(KEY_PREFIX + name);
}
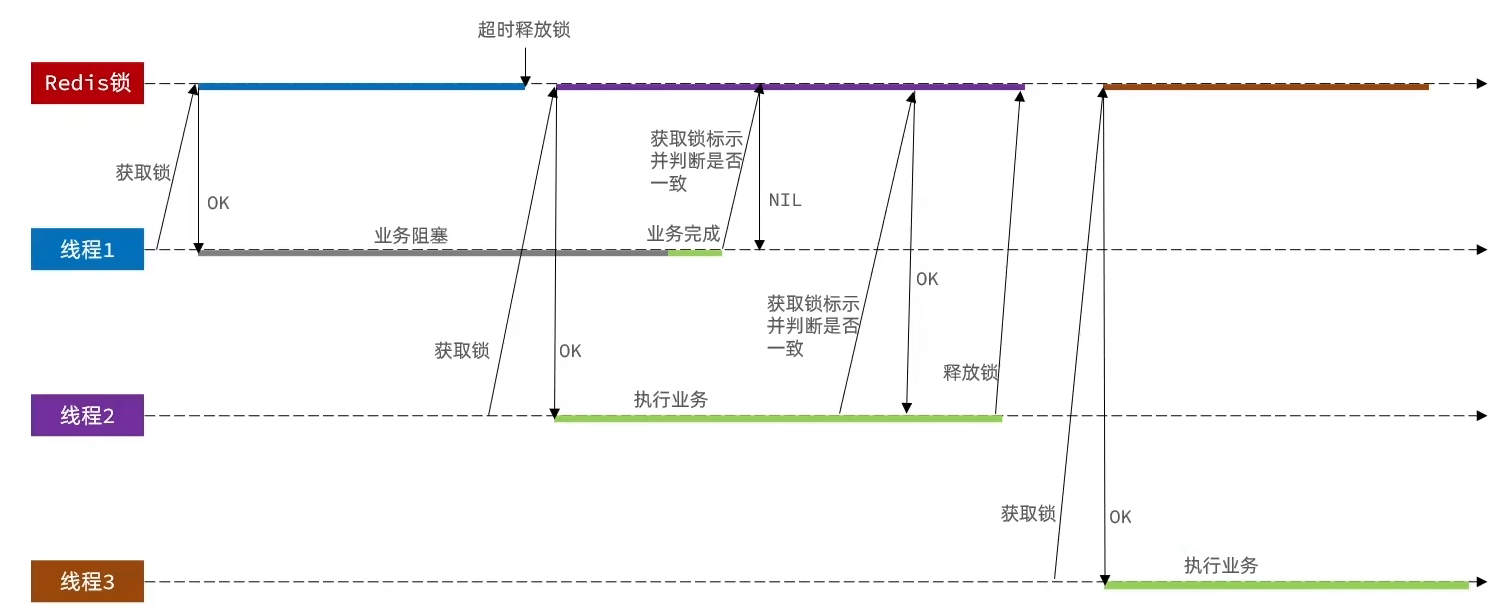
}这里还有问题,当线程执行完
if((threadId).equals(value))这段代码的时候,突然阻塞,以至于该线程持有的锁过期,其他线程拿到锁,而这时阻塞完之后,线程会释放掉其他线程的锁。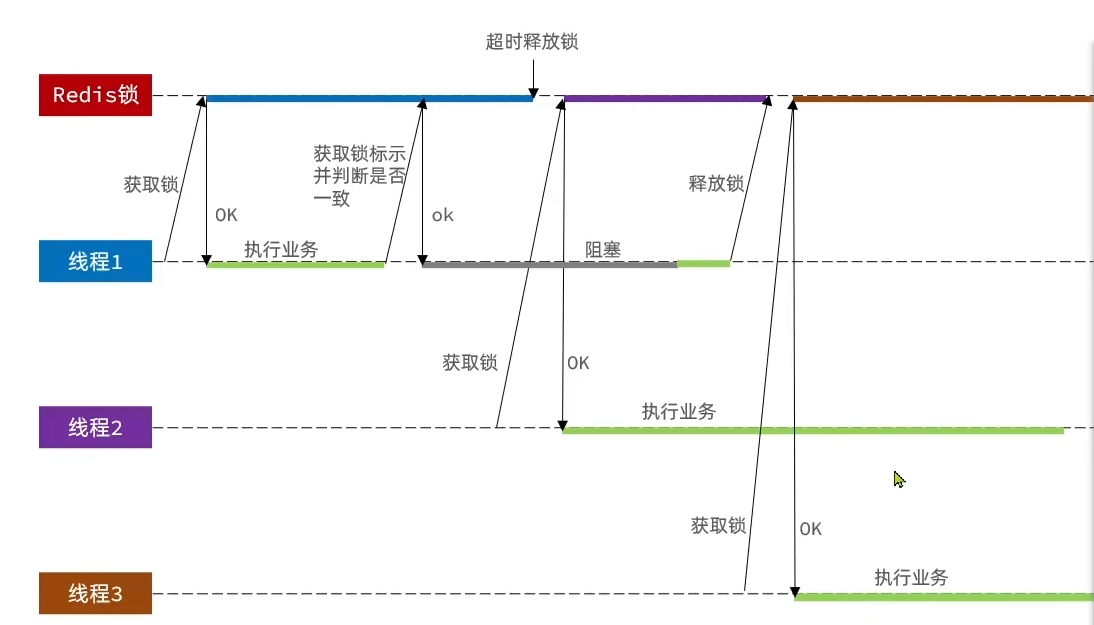
出现该问题的原因是判断锁标识和释放锁是两个操作,非原子性的操作。
如何解决这个问题呢?
4. Lua脚本
4.1 介绍
Lua 是一种极其轻量、高效且设计精巧的脚本语言,以“易于嵌入其他应用程序”闻名于世。
Lua 中只有一种复合数据结构--table,可以做数组、哈希表、对象甚至模块来使用,极大的简化了语言结构。
Lua 主要用于以下三大领域:
- 游戏开发
- 高性能网络服务
- 嵌入式与物联网
Lua 索引从1开始
Lua 代码简洁,基础代码示例:
lua-- 这是一个注释 local greeting = "Hello, Ethan!" function say_hello(name) print(greeting .. " Welcome to the world of " .. name) end -- Table 示例(数组与键值对混合) local skills = {"Coding", "Gaming", version = 5.4} say_hello("Lua")
4.2 为什么Redis中可以使用Lua完成操作(读取-修改-写入)的原子化?
4.2.1 串行执行机制
Redis 的核心处理逻辑是单线程的。当你发送一个 EVAL 命令运行 Lua 脚本时,Redis 会将整个脚本作为一个单一的、不可分割的命令放入队列。
- 阻塞特性:在脚本执行期间,Redis 不会处理任何其他客户端发送的命令。
- 无竞态条件:因为同一时间只有一个脚本在运行,所以不会出现两个客户端同时修改同一个键而导致的数据错乱。
4.2.2 脚本的完整性
Redis 保证脚本中的所有操作要么全部执行(在不发生崩溃的前提下),要么在脚本解析阶段报错。
注意:这里的“原子性”与传统关系型数据库(如 MySQL)的 ACID 原子性略有不同。如果脚本在执行到一半时发生语法错误或运行时错误(例如对 String 类型执行了 Hash 操作),Redis 不会自动回滚已经执行成功的命令。它更多是指“执行过程不被中断”。
4.3 使用
总结:在Redis中使用 EVAL 命令调用Lua脚本,Lua脚本中使用Redis提供的 redis.call() 或 redis.pcall() 命令使用Redis命令。
在 Redis 中使用 Lua 脚本,主要通过 EVAL 命令来实现。为了让你高效上手,Ethan,我们可以从基础语法、参数传递到实际案例来拆解。
4.3.1 核心命令:EVAL
EVAL 命令是执行 Lua 脚本的入口,其基本语法如下:
EVAL script numkeys key [key ...] arg [arg ...]- script: Lua 脚本内容。
- numkeys: 脚本中涉及到的 Redis Key 的数量。
- key [key ...]: 具体的 Key 列表,在脚本中通过
KEYS[1],KEYS[2]访问。 - arg [arg ...]: 附加参数,在脚本中通过
ARGV[1],ARGV[2]访问。
4.3.2 在脚本中调用 Redis
在 Lua 环境中,有两个函数可以执行 Redis 命令:
redis.call():遇到错误时直接抛出异常,阻止脚本继续运行。redis.pcall():遇到错误时会捕获错误并返回 Lua 表(Table),脚本可以继续执行。
4.3.3 实战案例:原子性“限流器”
假设你需要实现一个限流逻辑:10 秒内最多访问 5 次。如果用普通命令,读取计数、判断、加 1 是三个步骤,容易出现竞态。
使用 Lua 脚本可以将其合并为一个原子操作:
-- KEYS[1]: 限流的业务 Key (如 "user:123:login_limit")
-- ARGV[1]: 过期时间 (如 "10")
-- ARGV[2]: 限制次数 (如 "5")
local count = redis.call("GET", KEYS[1])
if count and tonumber(count) >= tonumber(ARGV[2]) then
return 0 -- 超过限制,返回失败
end
local res = redis.call("INCR", KEYS[1])
if res == 1 then
redis.call("EXPIRE", KEYS[1], ARGV[1])
end
return 1 -- 成功如何在 Redis 命令行调用:
EVAL "local count = redis.call('GET', KEYS[1]) if count and tonumber(count) >= tonumber(ARGV[2]) then return 0 end local res = redis.call('INCR', KEYS[1]) if res == 1 then redis.call('EXPIRE', KEYS[1], ARGV[1]) end return 1" 1 rate:limit:key 10 54.3.4 进阶:使用 SCRIPT LOAD 与 EVALSHA
由于 Lua 脚本可能很长,每次发送脚本会浪费带宽。Redis 提供了缓存机制:
- 加载脚本:使用
SCRIPT LOAD "script_content",Redis 会返回一个 SHA1 校验和。 - 执行脚本:使用
EVALSHA "sha1_value" numkeys keys args。
这样后续调用只需传递 40 位的 SHA1 字符串即可,非常适合高频操作。
4.3.5 最佳实践与注意事项
保持 Key 的参数化
错误做法:在脚本里硬编码 redis.call("GET", "mykey")。
正确做法:通过 KEYS[1] 传入。
原因:Redis 集群模式下,Key 会根据插槽分布,参数化 Key 方便 Redis 预先判断脚本是否能在当前节点执行。
避免阻塞
Lua 脚本在执行时会锁定整个 Redis。请务必:
- 不要在脚本里写复杂的
for循环(处理万级以上数据)。 - 不要使用
KEYS *等高延迟操作。
调试建议
你可以使用 redis-cli --ldb --eval script.lua key1 , arg1 进入 Redis Lua Debugger(断点调试模式),这对于编写复杂逻辑非常有帮助。
4.3.6 Java中使用EVAL命令:调用redisTemplate的execute函数
4.4 setnx 方案的问题
- 锁不可重入:同一个线程无法重复获取一把锁
- 锁不可重试:获取锁失败,则返回false,无重试机制
- 超时释放:拿取锁超过一定时间后,线程会主动释放锁
- 主从一致性:主从节点存在同步延时问题,如果线程在主节点拿到了锁,因为延迟问题,没有及时的同步到从节点,而这时主节点宕机,从节点没有及时同步,会有并发安全问题。
1.5.3 Redisson
1.1 介绍
Redisson 是一个在Redis基础上实现的 Java 驻内存数据网格(In - Memory Data Grid),它不仅提供了一系列的分布式的 Java 常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。

Redisson主要包括分布式数据结构和分布式同步工具两部分,分布式数据结构是底层使用==Redis存储==的可供Java使用的数据结构,支持分布式的数据存储(集群数据共享),下面为Redisson的大致的层次结构。
┌─────────────────────────────────────────────────────┐ │ 你的业务代码 │ ├──────────────────┬──────────────────────────────────┤ │ 分布式数据结构 │ 分布式同步工具 │ │ RMap/RList... │ RSemaphore/RLock/RCountDown... │ ├──────────────────┴──────────────────────────────────┤ │ Redisson 核心(Netty + 编解码) │ ├─────────────────────────────────────────────────────┤ │ Redis 原语(String / Hash / List / │ │ Pub-Sub / Lua Script ...) │ └─────────────────────────────────────────────────────┘
1.2 Redisson使用场景
[Redisson的使用场景](../分布式/2. Redisson.md)
1.3 Redisson 入门
引入依赖
xml<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.13.6</version> </dependency>配置Redisson客户端
java@Configuration public class RedisConfig { @Bean public RedissonClient redissonClient() { // 配置类 Config config = new Config(); // 配置Redis config.useSingleServer().setAddress("redis://192.168.134.128:6379").setPassword("123456"); // 创建客户端 return Redisson.create(config); } }使用Redisson的分布式锁
java@Autowired private RedissonClient redissonClient; @Test void testRedissonClient() throws InterruptedException { // 创建锁(可重入) RLock lock = redissonClient.getLock("anyLock"); // tryLock 参数:获取锁最大等待时间,锁自动释放时间,单位 boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS); // 获取锁成功 if (isLock) { try{ System.out.println("执行业务!"); }finally { // 释放锁 lock.unlock(); } } }
1.4 Redisson 可重入锁原理
Redisson底层使用Lua脚本完成获取锁和释放锁的逻辑
Redisson使用hash结构存储锁,Value属性记录线程获取锁的次数,每次获取锁时,如果发现本线程已经获取过锁,则将value + 1

Redisson释放锁时,检查是否为本线程持有的锁,如果为本线程持有的锁,检查value值是否大于0,如果大于0,则将 value - 1,如果等于0,则将该锁删除
Redisson获取锁源码Lua脚本:
lua"if (redis.call('exists', KEYS[1]) == 0) then " + "redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + "redis.call('hincrby', KEYS[1], ARGV[2], 1); " + "redis.call('pexpire', KEYS[1], ARGV[1]); " + "return nil; " + "end; " + "return redis.call('pttl', KEYS[1]);"- 执行流程:
- 检查锁键是否存在:
- 如果不存在(
exists返回 0),则创建锁:使用hincrby将持有者计数加1,设置过期时间(pexpire),返回nil(表示成功获取锁)。
- 如果锁键存在,检查当前线程是否已持有锁:
- 如果已持有(
hexists返回 1),则增加持有计数(支持重入),刷新过期时间,返回nil。
- 否则,返回锁键的剩余生存时间(
pttl),表示锁被其他线程占用,当前尝试失败
- 执行流程:
Redisson释放锁源码Lua脚本
lua"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " + "return nil;" + "end; " + "local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " + "if (counter > 0) then " + "redis.call('pexpire', KEYS[1], ARGV[2]); " + "return 0; " + "else " + "redis.call('del', KEYS[1]); " + "redis.call('publish', KEYS[2], ARGV[1]); " + "return 1; " + "end; " + "return nil;",- 执行逻辑:
- 检查锁是否存在:使用
hexists检查键KEYS[1](锁名称)中是否存在字段ARGV[3](线程锁名称)。如果不存在,返回nil,表示当前线程未持有锁。 - 递减计数器:如果存在,使用
hincrby将字段ARGV[3]的值减1,获取新计数器值。 - 判断是否完全解锁:
- 如果计数器 > 0,使用
pexpire设置键的过期时间为ARGV[2](租约时间),返回0,表示锁仍被持有(可重入)。 - 如果计数器 <= 0,删除键
KEYS[1],并使用publish向通道KEYS[2]发送解锁消息ARGV[1],返回1,表示完全解锁。
- 如果计数器 > 0,使用
- 异常处理:脚本末尾的
return nil;不会执行,仅作为安全兜底
- 检查锁是否存在:使用
- 执行逻辑:
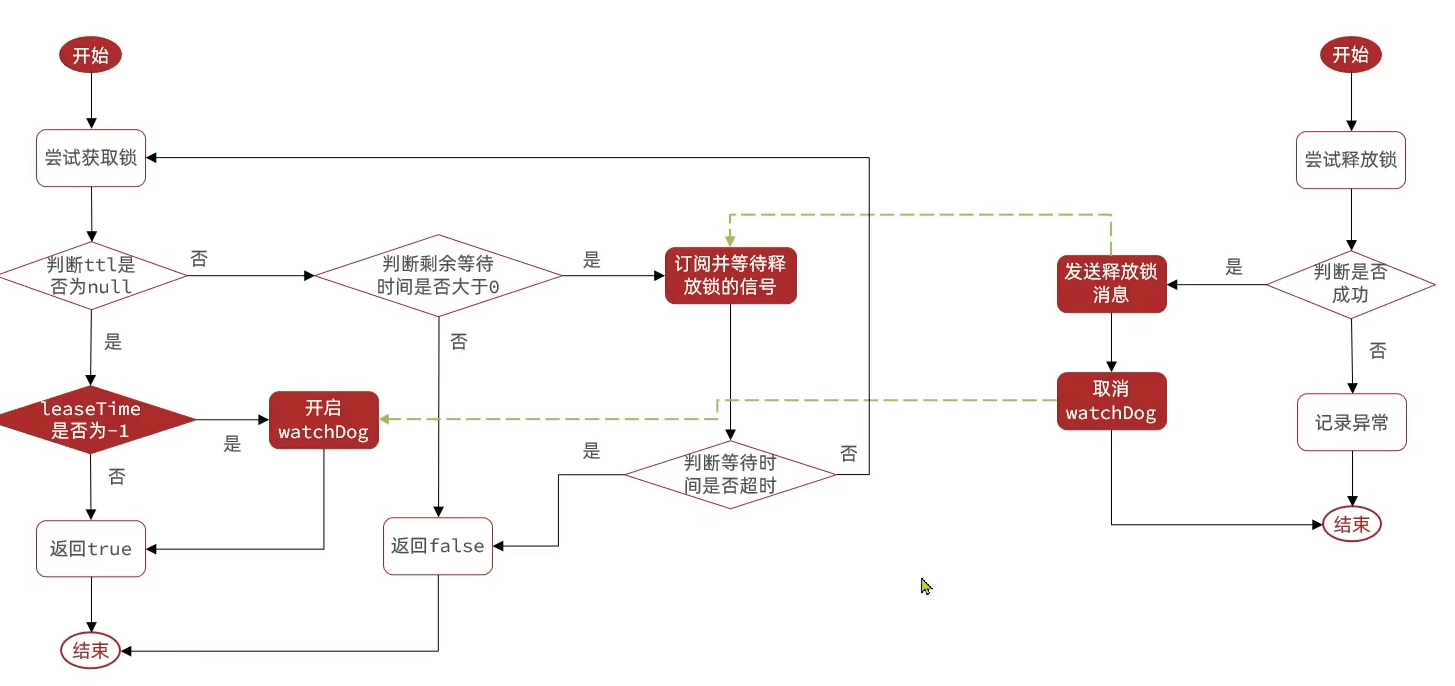
1.5 Redisson解决超时释放和重试问题
1.6 Redisson分布式锁主从一致性问题
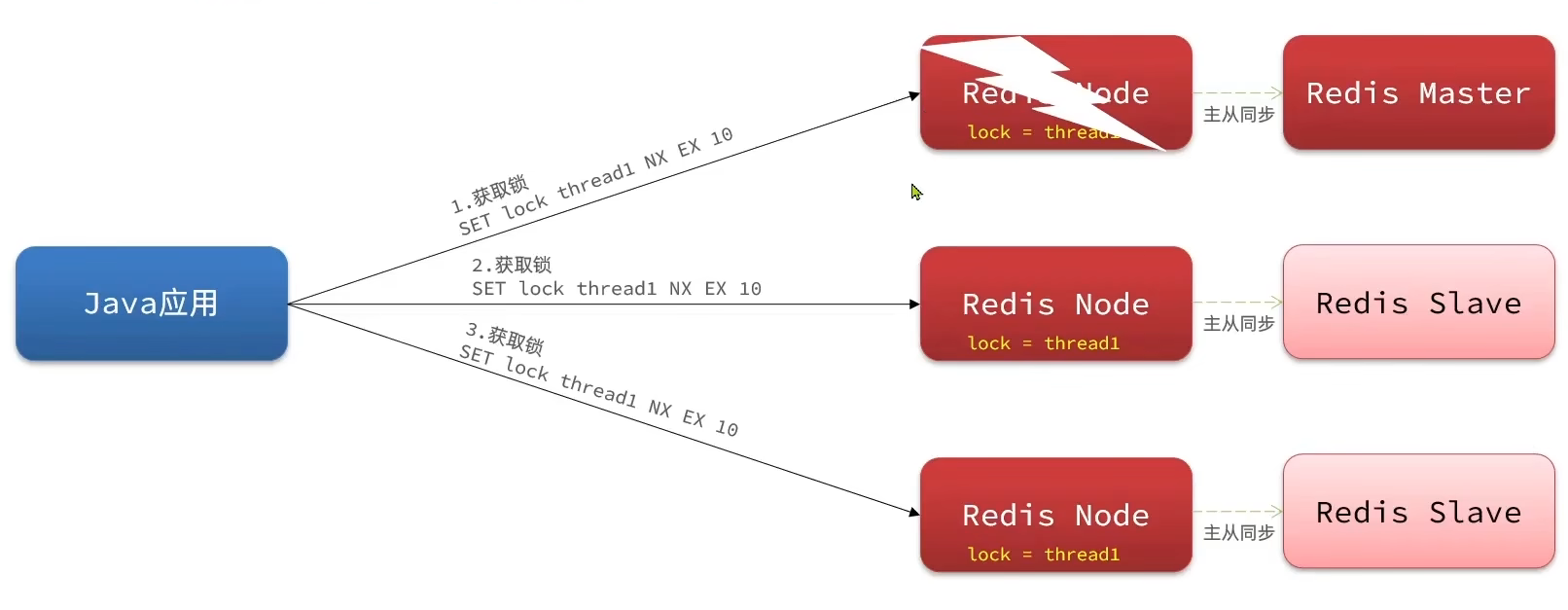
- Redisson分布式锁针对主从一致性问题的解决方案是
Redlock,在Java中的实现为MultiLock(联锁),即:线程只有拿到过半数的锁的时候,才认定为其持有锁。 - 图中是3个独立Master节点(每个Master带一个Slave),thread1 同时向3个节点发送加锁请求,但是节点1宕机了,线程只拿到过半数锁,但是这种情况算该线程持有锁,这时即便有其他线程过来加锁,其最多只能拿到一个锁,达不到过半数锁,所以依然能达到锁的互斥性。
- 这张图里指的就是联锁,但是实际底层实现是==多数派投票 + 有效时间校验 + 失败自动释放==,为Redlock在Java中的实现,==目前RedLock方法已弃用==,Java实际使用的MultiLock是==所有节点都获取锁==才算有效。
1.7 Redisson分布式锁总结
- 可重入,利用 hash 结构记录线程 id 和重入次数
- 可重试,利用信号量和 PubSub 功能实现等待、唤醒,获取锁失败的重试机制
- 超时续约:利用 watchDog, 每隔一段时间 (releaseTime/ 3 ),重置超时时间
1.6 Redis优化秒杀
1.6.1 问题
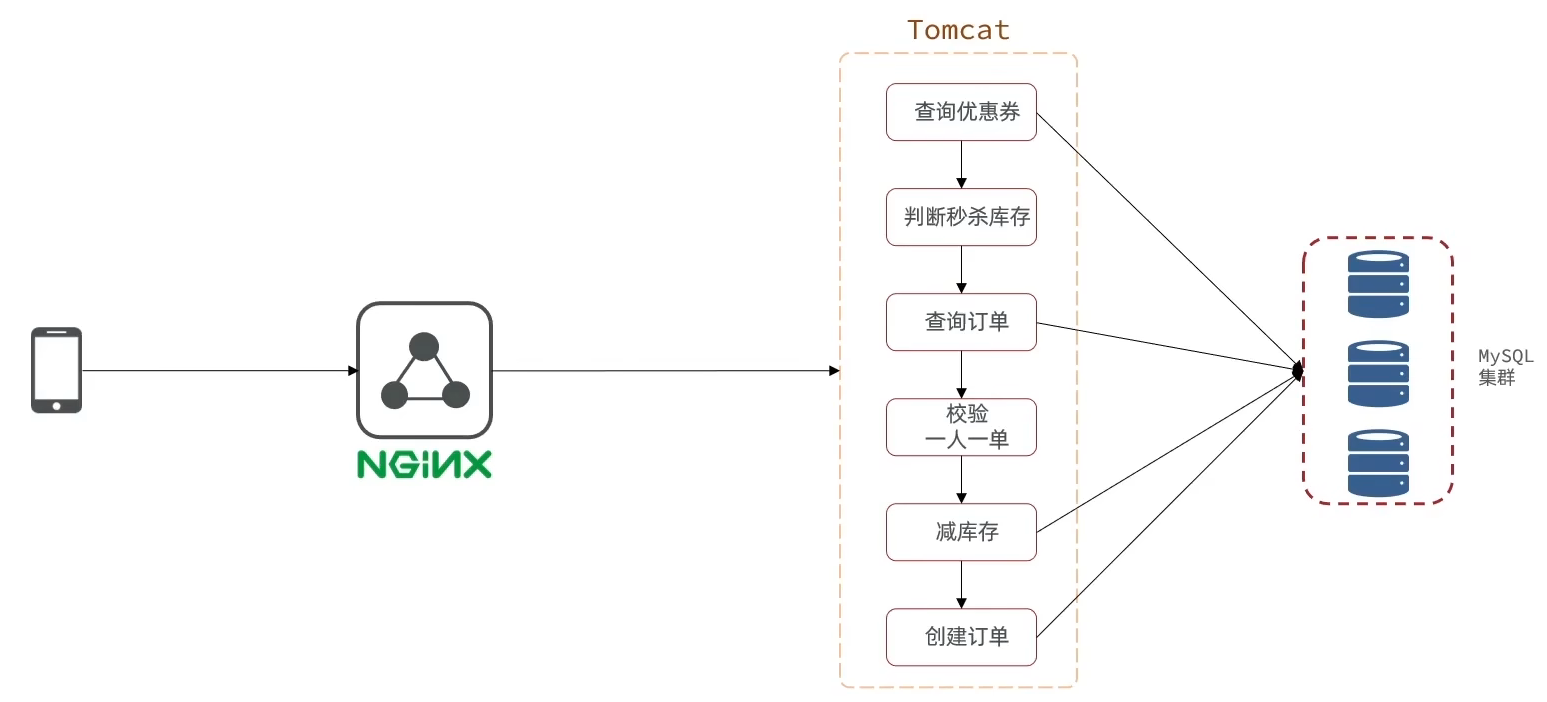
目前优惠券秒杀的业务是串行执行的,并且业务流程查询优惠券、查询订单、减库存、创建订单这四个操作都是在MySQL数据库中完成的,整体业务比较耗时,并发能力弱。
1.6.2 解决思路
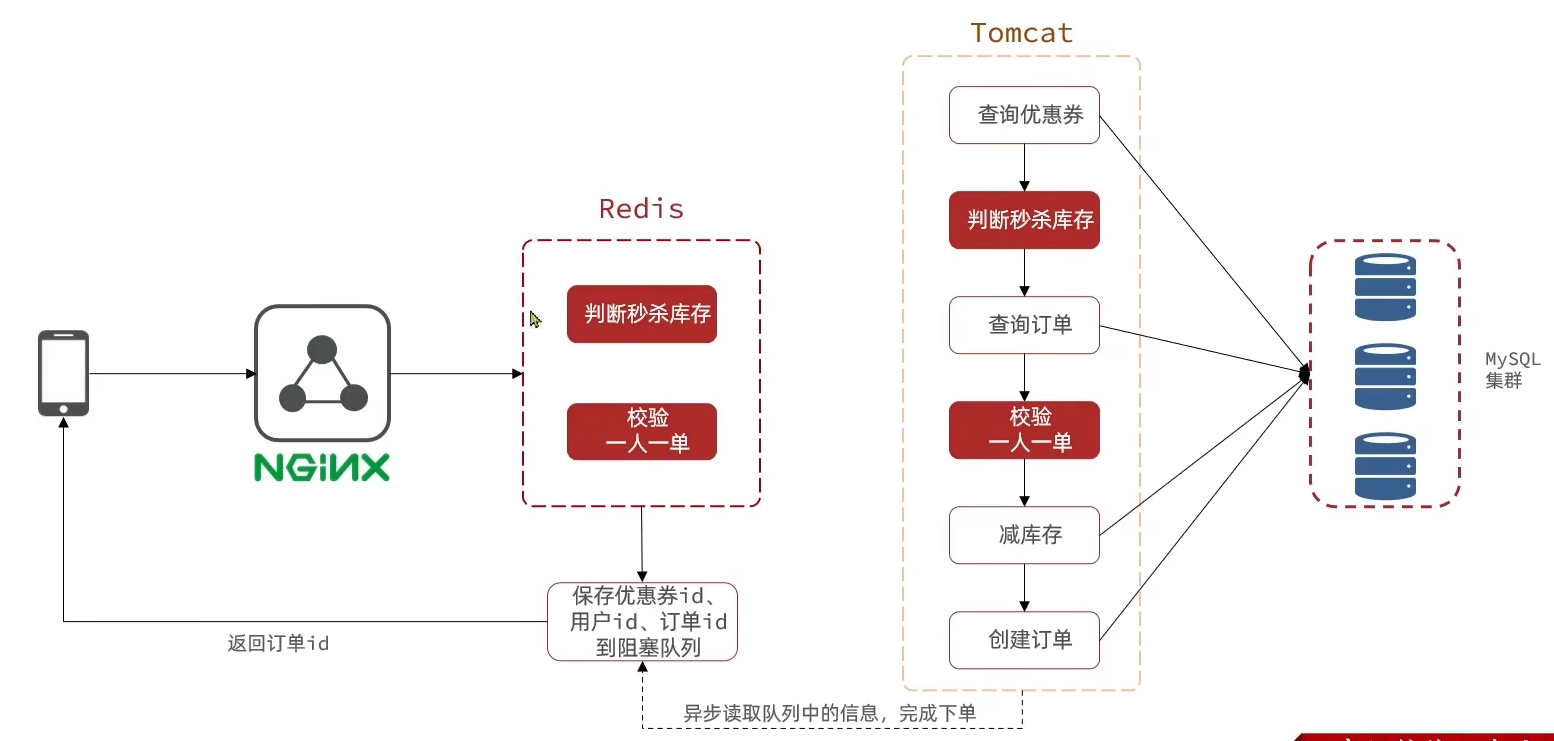
将判断库存是否充足、一人一单的业务放在Redis中执行
异步进行判断秒杀资格和执行秒杀操作两个业务
1.6.3 生成实际可执行方案
进行秒杀活动时,首先在Redis中预热,将优惠券信息预热到Redis中
使用 string 类型存储优惠券库存
key : 优惠券id ,value : 库存使用 Set 类型存储购买过优惠券的用户的信息
key : 优惠券id , value : 用户id
在执行完校验一人一单操作后,预生成订单到Redis中,防止判断资格和执行秒杀业务两步操作中间的时间有其他线程误入
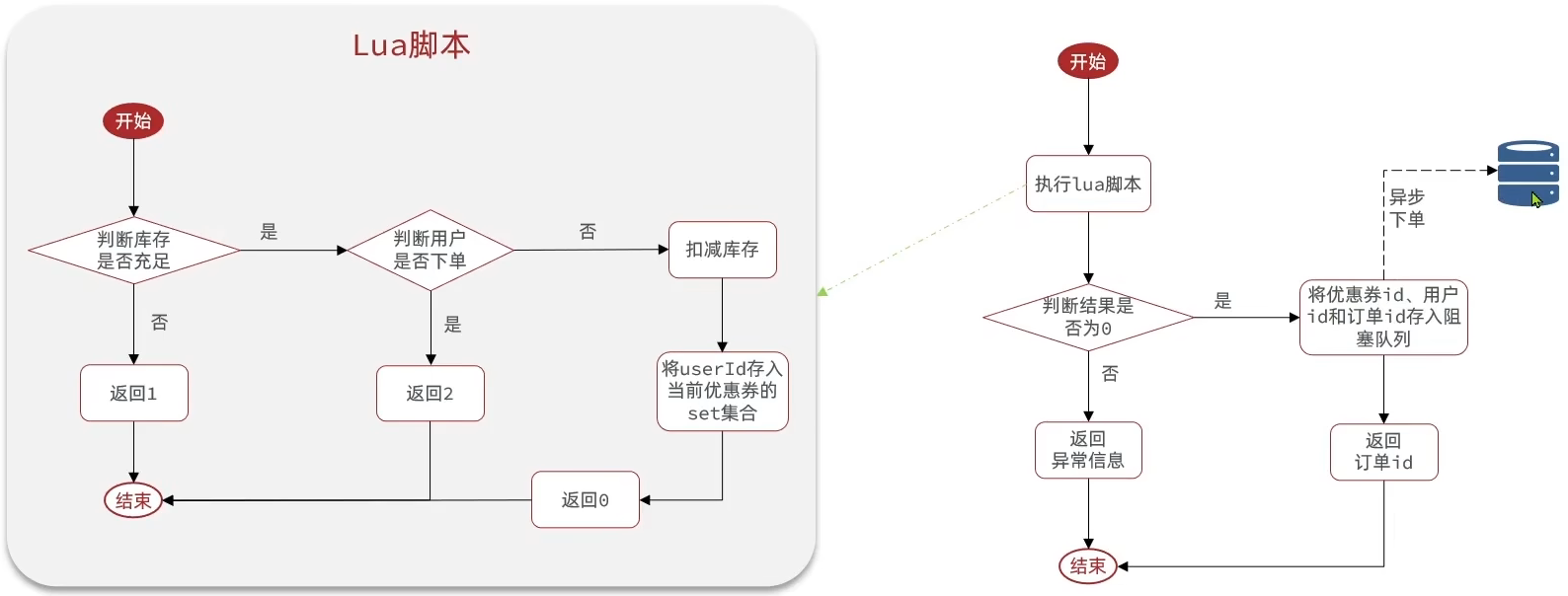
判断秒杀库存、校验一人一单、预下单三个操作写为Lua脚本,实现业务的原子性。并且Redis是单线程模型的,所以在单节点情况下,不会有并发问题;如果在集群环境,通过使用
{}语法,例如将 Key 命名为stock:{vid:7}和order:{vid:7},Redis 会仅根据花括号内的内容计算哈希值。这样,这两个 Key 就一定会落在同一个 Slot 中,由同一个 Redis 节点处理。流程图:
1.6.4 代码开发
需求
- 新增秒杀优惠券的同时,将优惠券的信息保存到Redis中
- 基于Lua脚本,判断秒杀库存、一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券ID和用户ID封装后存入阻塞队列
- 开启线程任务,不断的从阻塞队列中获取信息,实现异步下单功能
大致代码
javaprivate BlockingQueue<VoucherOrder> orderTasks = new ArrayBlockingQueue<>(1024 * 1024); public static final ExecutorService SECKILL_ORDER_EXECUTOR = Executors.newSingleThreadExecutor(); // 当前类初始化后执行 @PostConstruct private void init() { SECKILL_ORDER_EXECUTOR.submit(new VoucherOrderHandler()); } // 异步线程一直在等待阻塞队列中是否有订单信息,如果有就取出订单信息进行处理 private class VoucherOrderHandler implements Runnable { @Override public void run() { while (true) { // 1. 查看阻塞队列是否有订单信息 try { VoucherOrder voucherOrder = orderTasks.take(); // 2. 有就创建订单 handleVoucherOrder(voucherOrder); } catch (Exception e) { log.error("处理订单异常", e); } } } }
1.6.5 基于阻塞队列完成异步秒杀业务的问题
- 阻塞队列的内存限制问题
- 数据安全问题:当下单的任务被丢弃后,有数据丢失问题
1.7 Redis消息队列实现异步秒杀
1.7.1 概念
消息队列(Message Queue),字面意思就是存放消息的队列,最简单的消息队列有三个角色:
消息队列:存储和管理消息,也被称为消息代理(Message Broker)
生产者:发送消息到消息队列
消费者:从消息队列获取消息并处理消息
消息队列是一种异步通信机制,允许不同服务/组件之间通过"发消息"来解耦协作。
常用的两种消息类型:
- Topic:发布/订阅类型,消息会广播出去
- Queue:点对点类型,消息只会被一个消费者拿到
消息队列相比阻塞队列解决了什么问题?
- 消息队列的内存独立于JVM,解决了阻塞队列的内存限制问题
- 消息队列确保消息至少被消费一次,解决了数据丢失的问题
1.7.2 解决了什么问题
- 解耦:订单服务完成下单后,不需要直接调用库存、物流、通知服务,只需发一条消息。各服务独立演进。
- 异步:发送短信、生成报表等耗时操作,丢进队列后立刻返回响应,提升接口吞吐量。
- 削峰填谷:秒杀场景下,瞬间涌入的请求先堆在队列里,消费者按自身处理能力慢慢消费,避免数据库被打垮。
1.7.3 常用消息队列区别以及选型要点
RocketMQ vs Kafka vs RabbitMQ
| 对比维度 | RocketMQ | Kafka | RabbitMQ |
|---|---|---|---|
| 出身 | 阿里开源,Apache 顶级项目 | LinkedIn 开源,Apache 顶级项目 | Pivotal,基于 AMQP 协议 |
| 定位 | 业务消息 | 流式数据/日志 | 业务消息 |
| 吞吐量 | 十万级/秒 | 百万级/秒 | 万级/秒 |
| 延迟 | 毫秒级 | 毫秒~秒级(批量发送) | 微秒~毫秒级 |
| 可靠性 | 高,支持同步刷盘 | 高,依赖副本机制 | 高,支持持久化+镜像队列 |
| 消息顺序 | ✅ 支持局部有序 | ✅ 分区内有序 | ❌ 不保证 |
| 事务消息 | ✅ 原生支持 | ❌ 不支持 | ❌ 不支持 |
| 延迟消息 | ✅ 原生支持 | ❌ 不支持 | ⚠️ 插件支持 |
| 死信队列 | ✅ 原生支持 | ❌ 需自行实现 | ✅ 原生支持 |
| 消息回溯 | ✅ 支持按时间回溯 | ✅ 支持按 offset 回溯 | ❌ 不支持 |
| 消费模式 | Push / Pull | Pull | Push |
| 路由能力 | 简单 | 简单 | 强(Exchange 路由规则灵活) |
| 协议 | 私有协议 | 私有协议 | AMQP(标准协议) |
| Spring Boot 集成 | ⭐⭐⭐ rocketmq-spring | ⭐⭐⭐ spring-kafka | ⭐⭐⭐⭐ spring-amqp(最成熟) |
| 运维复杂度 | 中 | 高(依赖 ZooKeeper/KRaft) | 低(管理界面友好) |
| 适用场景 | 电商、金融、订单、支付 | 日志收集、大数据、埋点 | 中小型业务、微服务解耦 |
| 国内使用 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
一句话选型建议:
- 做业务系统(订单/支付/通知) → 优先 RocketMQ,事务消息和延迟消息开箱即用
- 做日志/埋点/大数据管道 → 优先 Kafka,吞吐量无敌
- 团队小/快速上手/需要灵活路由 → 优先 RabbitMQ,运维最简单
1.7.4 Redis实现消息队列
Redis 提供了三种不同的方式来实现消息队列:
- list 结构:基于 List 结构模拟消息队列
- PubSub: 基本的点对点消息模型
- Stream :比较完善的消息队列模型
1.7.5 基于List结构实现Redis消息队列
实现思路:
队列是入口和出口不在一边,因此我们可以利用: LPUSH 结合 RPOP 、或者 RPUSH 结合 LPOP 来实现。不过要注意的是,当队列中没有消息时 RPOP 或 LPOP 操作会返回 null,并不像 JVM 的阻塞队列那样会阻塞并等待消息。因此这里应该使用 BRPOP 或者 BLPOP 来实现阻塞效果。

基于List的消息队列有哪些优缺点?
- 优点
- 利用 Redis 存储,不受限于 JVM 内存上限
- 基于 Redis 的持久化机制,数据安全性有保证
- 可以满足消息有序性
- 缺点
- 无法避免消息丢失
- 只支持单消费者
- 优点
1.7.6 基于PubSub的消息队列
- PubSub (发布订阅)是 Redis2.0 版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个 channel ,生产者向对应 channel 发送消息后,所有订阅者都能收到相关消息。
- SUBSCRIBE channel [channel ]:订阅一个或多个频道
- PUBLISH channel msg :向一个频道发送消息
- PSUBSCRIBE pattern[pattern] :订阅与 pattern 格式匹配的所有频道
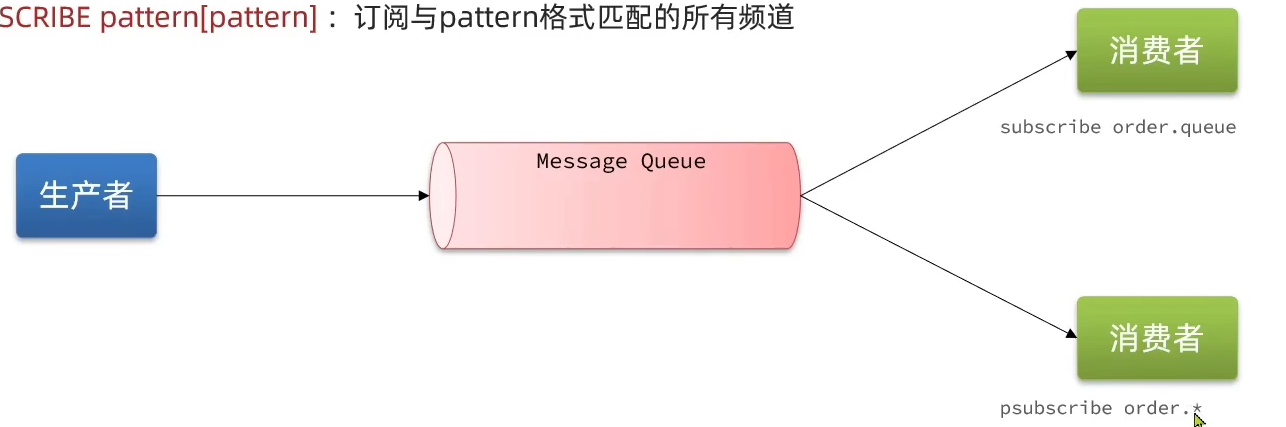
- 基于PubSub的消息队列的优缺点?
- 优点:
- 采用发布订阅模型,支持多生产、多消费
- 缺点:
- 不支持数据持久化,消息没有被订阅者收到,就会遗失
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
- 优点:
1.7.7 基于Stream实现的消息队列
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息:
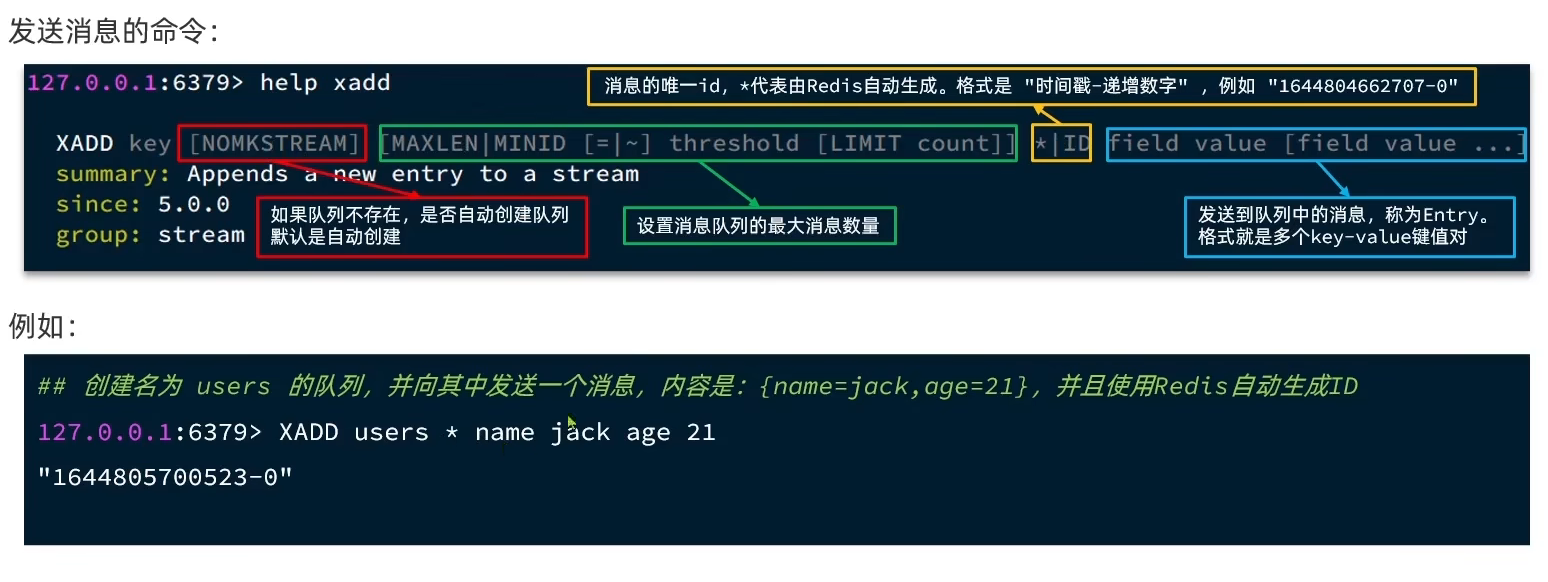
读取消息:
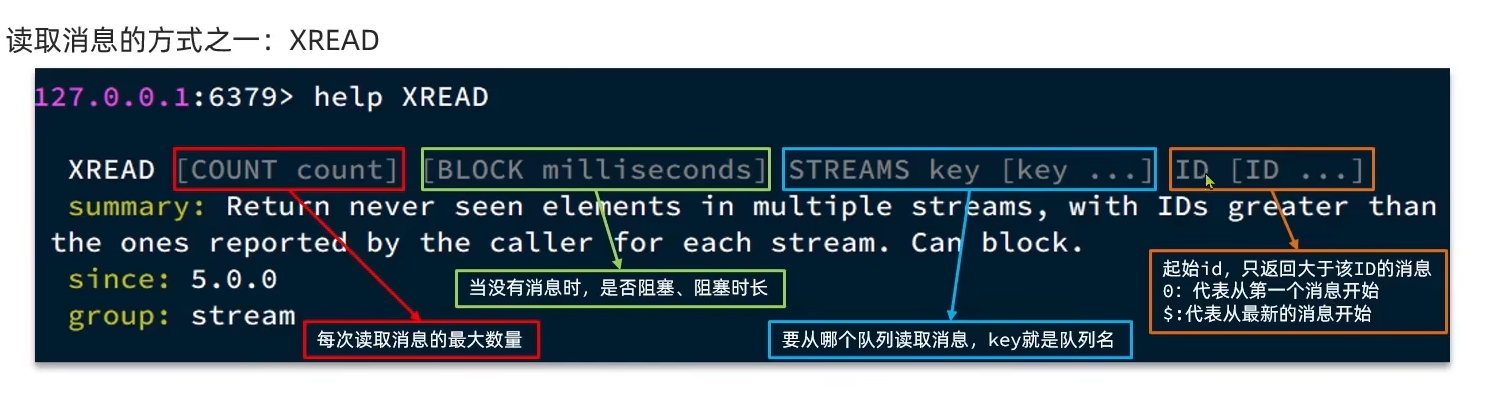
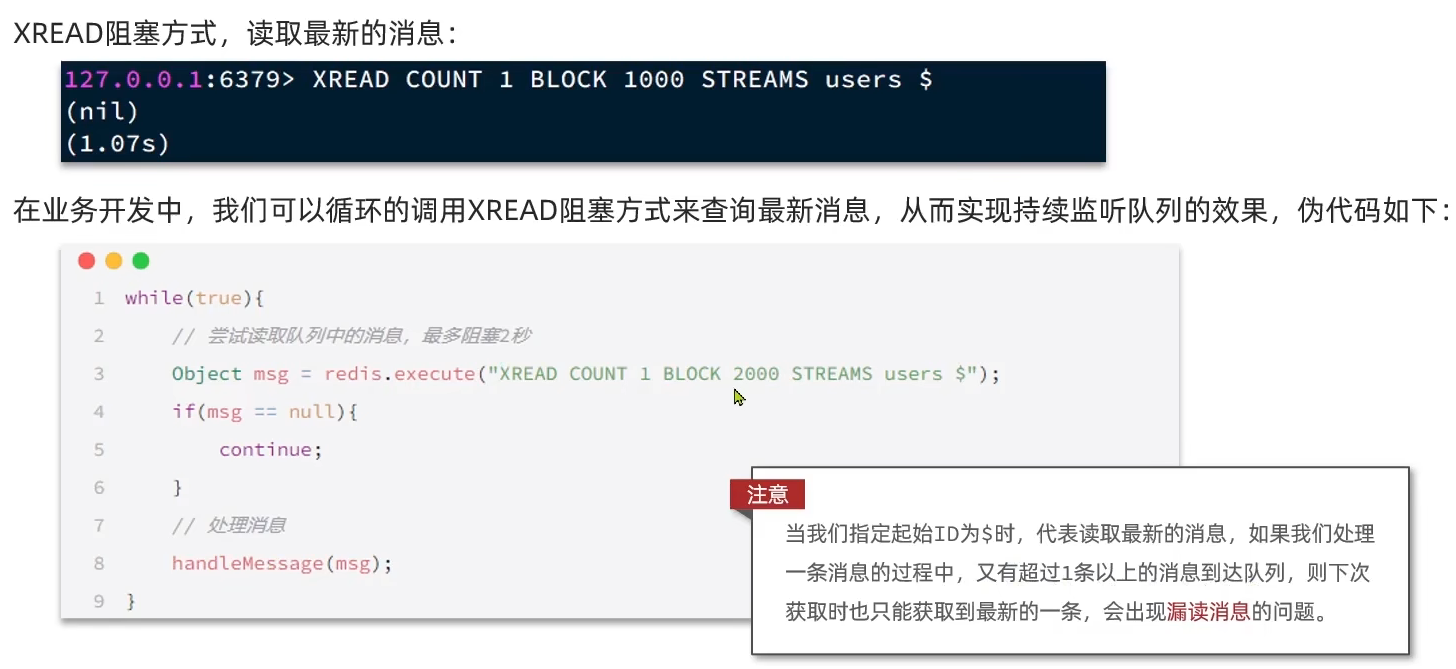
STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
消费者组

消费者组常用命令


消费者监听消息基本思路:
